Three-line (though non-standard) interlinear glossing
Still thinking about interlinear glossing for my language learning project. The leizig.js library is great but my use case isn’t really what the author had in mind. I really just need to display a unit consisting of the word as it appears in the text, the lemma for that word form, and (possibly) the part of speech. For academic linguistics purposes, what I have in mind is completely non-standard.
The other issue with leizig.js for my use case is that I need to be able to respond to click events on individual words so that they can be tagged, defined or otherwise worked with. It’s straightforward how I could apply CSS id attributes to word-level elements to support that functionality.
So I’m back to a CSS-only solution.
Here’s what a three-line CSS-only interlinear glossing display might look like:
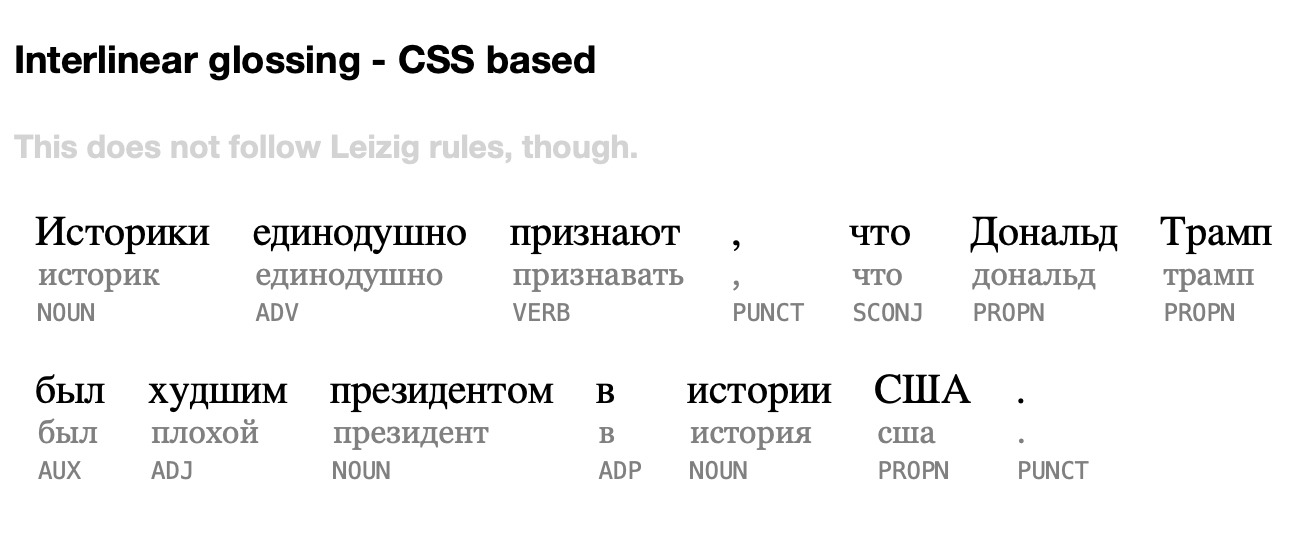
You can find the code - in progress, as always, in a JSFiddle.
One my priorities is going to be dealing with punctuation. It looks messy and unrefined right now. First, the punctuation marks need to be glommed onto the previous word rather than standing alone. Second, there’s no need to display either a lemma or a POS for punctuation marks. It’s going to need either JavaScript running on the page to dynamically deal with the UI, or something on the backend. Most likely the former.
