A small utility to parse and explain ARINC 424 records
The ARINC 424 specification is the universally accepted standard for encoding aeronautical navigation data. Databases that follow it store that data in fixed-length, 132-character records. I created a utility that parses a single ARINC 424 record and prints the fields along with column numbers and plain-language explanations. The Python arinc424 module does the heavy lifting; I provide a wrapper around it, plus the logic that maps fields to the column numbers used in the official specification.
Example ARINC 424 record
A typical record, one of thousands in the FAA Coded Instrument Flight Procedures (CIFP) dataset, looks like this:
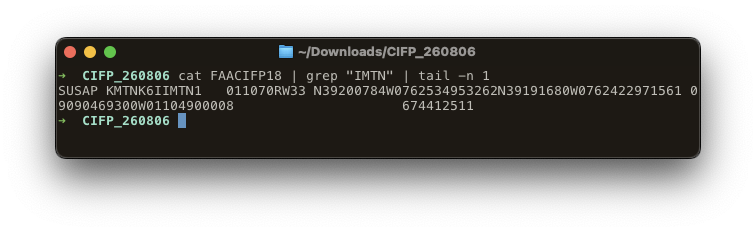
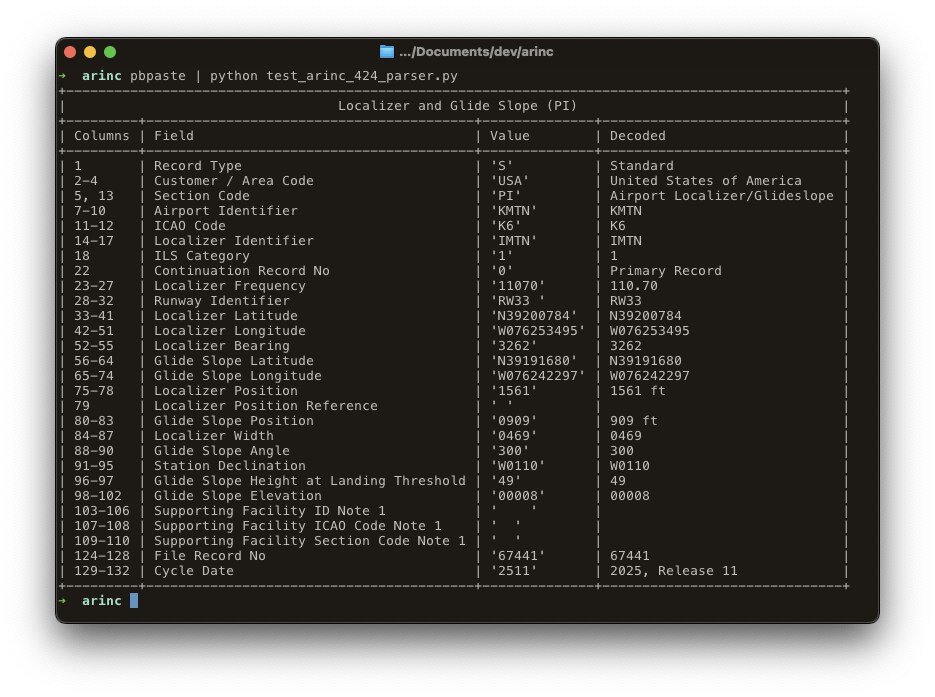
This is for the IMTN localizer at KMTN. The utility breaks it down into human-readable information:
Installation
The code lives in arinc424_explainer. You will need pyenv, pyenv-virtualenv, and Python 3.12.
Clone the repository:
git clone https://github.com/NSBum/arinc424_explainer.git
cd arinc424_explainerInstall a Python version if you do not already have one:
pyenv install 3.12.11Create and activate a virtualenv:
pyenv virtualenv 3.12.11 arinc-3.12.11
pyenv local arinc-3.12.11pyenv local writes .python-version, so this environment is selected automatically whenever you are in the project directory. Confirm:
python --version # should report 3.12.x from arinc-3.12.11
which python # should point at the arinc-3.12.11 virtualenvIf you previously ran pyenv shell, clear it so the local env takes effect:
pyenv shell --unsetInstall the dependencies:
pip install -r requirements.txtThat pulls in arinc424 and its dependencies.
Usage
Pipe a 132-character ARINC 424 record into the script. On macOS, the clipboard is convenient:
pbpaste | python test_arinc_424_parser.pyOr feed a record from a file:
python test_arinc_424_parser.py < record.txtNotes
I have only tested this on macOS, but I have no reason to suspect that it wouldn’t work on other platforms. Obviously pbpaste wouldn’t be available outside of macOS, so you would have to adapt. Apart from that, it should run.
You can grab the code from arinc424_explainer on GitHub. Contributions are welcome — feel free to open an issue or pull request. If you have questions or run into trouble, see my contact page.
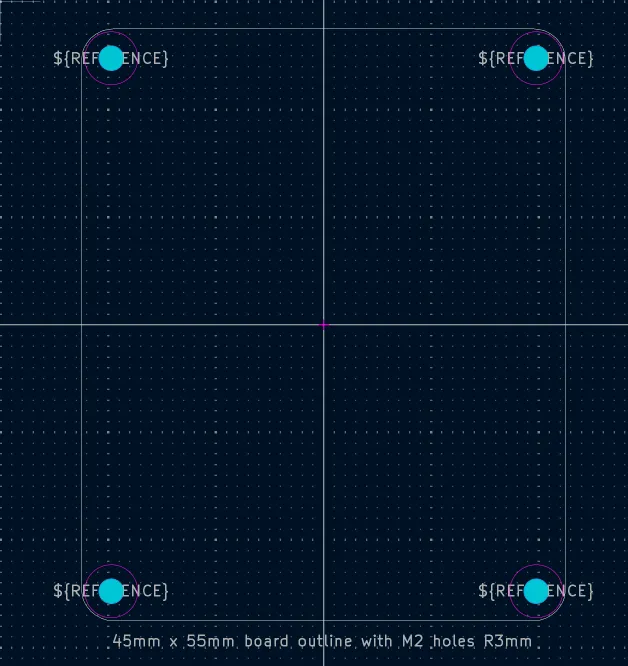 PCB fabricators require a board outline on the `Edge.Cuts` layer to specify the board size and shape. While drawing the board outline in the PCB editor is straightforward and uses the standard line and shape drawing tools, it is convenient to retain standardized board outlines and related parts, such as fasteners, as reusable footprints. During the board layout process, you can simply plop a board outline, along with perfectly-placed mounting holes into the editor and you can concentrate on placing components and routing. Also, having a standard library of board outlines gives you a predictable set of size choices for enclosures and for ordering SMD stencils.
PCB fabricators require a board outline on the `Edge.Cuts` layer to specify the board size and shape. While drawing the board outline in the PCB editor is straightforward and uses the standard line and shape drawing tools, it is convenient to retain standardized board outlines and related parts, such as fasteners, as reusable footprints. During the board layout process, you can simply plop a board outline, along with perfectly-placed mounting holes into the editor and you can concentrate on placing components and routing. Also, having a standard library of board outlines gives you a predictable set of size choices for enclosures and for ordering SMD stencils.
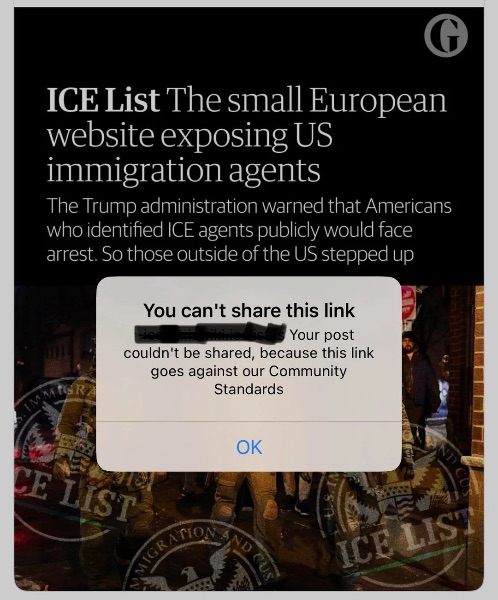 Facebook and Reddit are blocking access to a site that unmasks otherwise anonymous ICE thugs. F*ck you Reddit and Facebook.
Facebook and Reddit are blocking access to a site that unmasks otherwise anonymous ICE thugs. F*ck you Reddit and Facebook.