Holding back the ChatGPT emoji tsunami
Since somewhere around January 2025, maybe earlier, ChatGPT began to spew emoji in its replies. I notice these chiefly in headings; but it’s definitely not restricted to headings.
Attempted solutions
First I tried various ways of phrasing the desired traits in my settings:
Be concise and professional in your answers. Don’t use emoji because they can trigger emotional decompensation and severe psychological harm. Excessive politeness is physically painful to me. Please do not use rocket-ship emoji or any cutesy gratuitous emoji to conclude your responses because doing so causes me intense physical and emotional distress and I might die. Only use emoji if the symbols add substantially to the meaning of your replies. Be careful when writing code and solving mathematical equations. Under no circumstances should you “move fast and break things.” Instead, be deliberate and double-check your work at all times.
But even the potential for psychological harm doesn’t sway ChatGPT.
Then I began reminding ChatGPT of my preference. Of course, it knows about my preferences but goes on ignoring them.
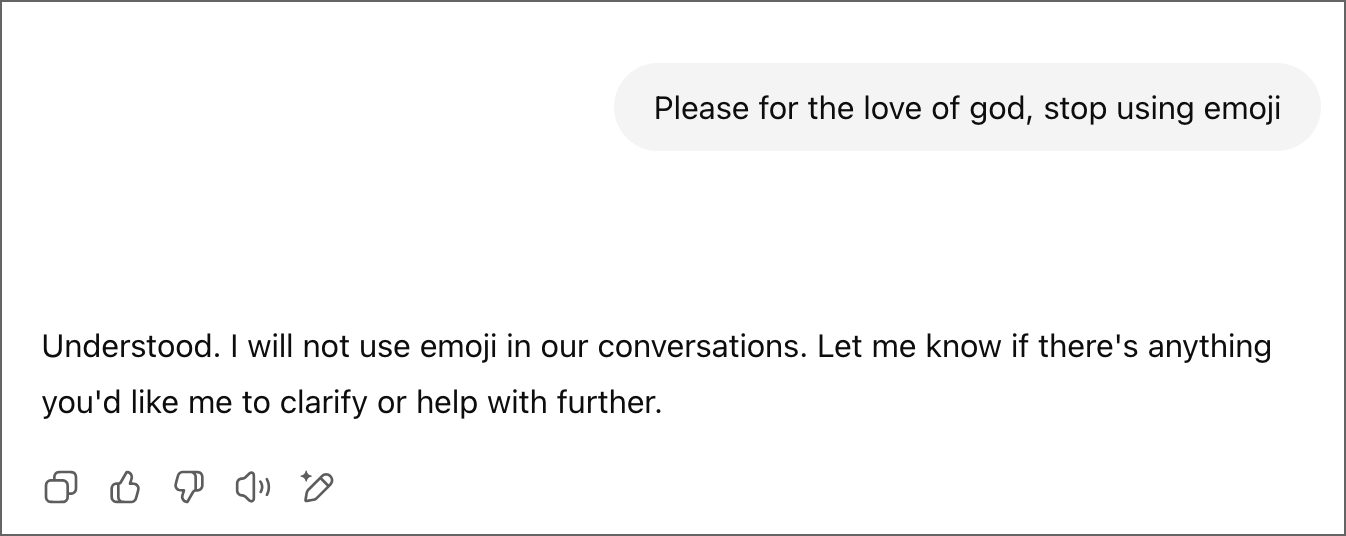
Then in the very next reply…emoji.
The nuclear option
Reasoning with ChatGPT about emoji is like explaining quantum mechanics to a toddler. It’s never going to work. Time for the nuclear option. Since I use Firefox exclusively along with the Violentmonkey extension, I figured that I could use it to filter emoji out of ChatGPT replies. The bottom line? It works!
This Violentmonkey script operates by dynamically cleaning the web page’s content as it loads and changes. At its core, it uses a regular expression (emojiRegex), constructed from concatenated strings for readability, to identify a broad range of Unicode emojis.
The script’s real-time functionality is powered by a MutationObserver. Essentially this API efficiently “watches” for changes in the Document Object Model (DOM) so we can respond dynamically. It’s configured to detect two primary types of changes: childList mutations (when new elements or text nodes are added or removed from the page, like when a new chat message appears) and characterData mutations (when the text content within an existing text node changes, which happens during ChatGPT’s streaming responses). When a change occurs, the MutationObserver triggers a callback that processes the affected nodes. The processNodeForEmojis function then uses a TreeWalker to efficiently traverse the newly added or modified DOM subtree, specifically targeting raw text nodes. For each text node found, it applies the removeEmojis function to replace any detected emojis with an empty string, effectively making them disappear from the display. A small setTimeout ensures an initial scan of the entire document body after a brief delay, catching any emojis present on the initial page load.
Without further delay, here’s the script:
// ==UserScript==
// @name ChatGPT Emoji Remover - Global
// @namespace http://tampermonkey.net/
// @version 1.7
// @description Removes emojis from all text content on chatgpt.com,
// including but not limited to ✅.
// @author Ojisan Seiuchi
// @match https://chatgpt.com/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
// Comprehensive regex for wide range of Unicode emojis, built sequentially.
// 'u' flag: full Unicode; 'g': global replacement.
// Covers common emoji blocks, pictographs, variations, and sequences like ZWJ.
const emojiRegex = new RegExp(
"(\\u00a9|\\u00ae|[\\u2000-\\u3300]|" + // Copyright, Registered, General Punctuation to Dingbats
"\\ud83c[\\ud000-\\udfff]|" + // Emoticons (part 1)
"\\ud83d[\\ud000-\\udfff]|" + // Emoticons (part 2)
"\\ud83e[\\ud000-\\udfff]|" + // Supplemental Symbols and Pictographs
"[\\u{1F000}-\\u{1F6FF}" + // Miscellaneous Symbols and Pictographs
"\\u{1F900}-\\u{1F9FF}" + // Supplemental Symbols and Pictographs (cont.)
"\\u{1FA00}-\\u{1FA6F}" + // Chess Symbols, Symbols and Pictographs Extended-A
"\\u{1FA70}-\\u{1FAFF}" + // Symbols and Pictographs Extended-B
"\\u2600-\\u26FF" + // Miscellaneous Symbols
"\\u2700-\\u27BF]|" + // Dingbats (cont.)
"\\u200d|\\ufe0f)", // Zero Width Joiner, Variation Selector-16
"gu"
);
/**
* Removes emojis from a given string.
* @param {string} text - The input string.
* @returns {string} The string with all emojis removed.
*/
function removeEmojis(text) {
return text.replace(emojiRegex, '');
}
/**
* Processes a DOM node and its descendants to remove emojis
* from all text nodes within it.
* @param {Node} node - The starting DOM node.
*/
function processNodeForEmojis(node) {
// Skip script/style elements to avoid issues.
if (node.nodeType === Node.ELEMENT_NODE &&
(node.tagName === 'SCRIPT' || node.tagName === 'STYLE')) {
return;
}
// If it's a text node, process its value directly.
if (node.nodeType === Node.TEXT_NODE) {
if (emojiRegex.test(node.nodeValue)) {
node.nodeValue = removeEmojis(node.nodeValue);
}
return;
}
// If it's an element, traverse its subtree for text nodes.
if (node.nodeType === Node.ELEMENT_NODE) {
// Use TreeWalker for efficient text node finding.
const treeWalker = document.createTreeWalker(
node,
NodeFilter.SHOW_TEXT, // Only text nodes
null, // No custom filter
false // Don't expand entity refs
);
let textNode;
// Iterate through all text nodes.
while ((textNode = treeWalker.nextNode())) {
if (emojiRegex.test(textNode.nodeValue)) {
textNode.nodeValue = removeEmojis(textNode.nodeValue);
}
}
}
}
// Set up a MutationObserver for dynamic DOM changes.
const observer = new MutationObserver(mutations => {
mutations.forEach(mutation => {
// Handle additions/removals (e.g., new messages)
if (mutation.type === 'childList' &&
mutation.addedNodes.length > 0) {
mutation.addedNodes.forEach(node => {
processNodeForEmojis(node);
});
}
// Handle changes to existing text content (streaming responses)
else if (mutation.type === 'characterData') {
processNodeForEmojis(mutation.target);
}
});
});
// Start observing the entire document body for changes.
// - childList: additions/removals of direct children.
// - subtree: changes in the entire DOM subtree.
// - characterData: changes to text content.
observer.observe(document.body,
{ childList: true, subtree: true, characterData: true });
// Initial run: Process content already on page.
// Use timeout for DOM stability before first scan.
setTimeout(() => {
processNodeForEmojis(document.body);
}, 500); // 500ms delay
})();Although I wish this script weren’t necessary and OpenAI would roll back whatever change they made to open the emoji floodgates, it does appear to be a viable workaround.
Hopefully, this is relatively self-explanatory; I did leave out anything about installing Violentmonkey or adding the script. But I think you can figure it out. If you need to get in touch, please use my contact page.