Although I’ve used Indigo — the macOS home automation ecosystem — for over a decade, I never picked up on the fact that Actions attached to Schedules, Triggers, and web UI elements are not executed sequentially. The application user interface strongly implies sequential execution, but not only is that not guaranteed, the app actually attempts to execute the actions in parallel.
See this note buried in the documentation:
Important! While you can order the actions in any order you like, Indigo will attempt to execute all actions in parallel. It’s not always possible for various reasons, but that’s the intent. If you want to order the execution, then you’ll need to add delays which will delay the action’s execution from the time of the event. So, if you have 3 actions and you want the first to execute immediately, the second to execute a minute after the event, and the third to execute two minutes after the event, then add a one minute delay to the second and a two minute delay after the third.
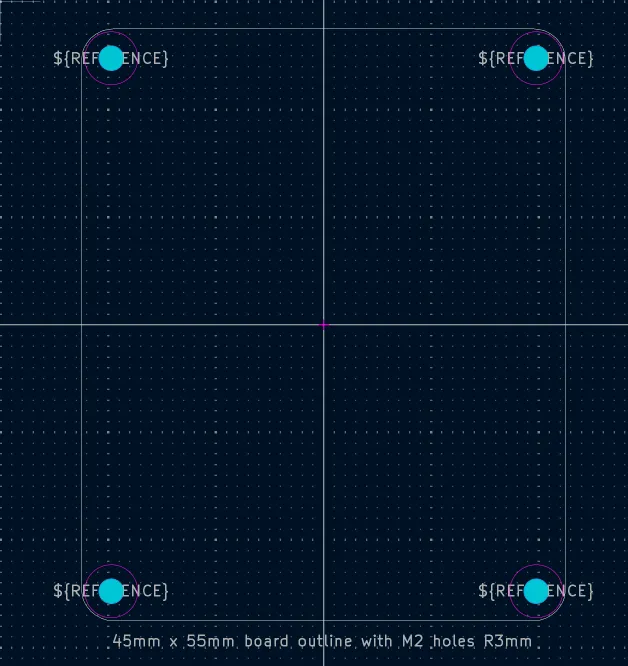 PCB fabricators require a board outline on the `Edge.Cuts` layer to specify the board size and shape. While drawing the board outline in the PCB editor is straightforward and uses the standard line and shape drawing tools, it is convenient to retain standardized board outlines and related parts, such as fasteners, as reusable footprints. During the board layout process, you can simply plop a board outline, along with perfectly-placed mounting holes into the editor and you can concentrate on placing components and routing. Also, having a standard library of board outlines gives you a predictable set of size choices for enclosures and for ordering SMD stencils.
PCB fabricators require a board outline on the `Edge.Cuts` layer to specify the board size and shape. While drawing the board outline in the PCB editor is straightforward and uses the standard line and shape drawing tools, it is convenient to retain standardized board outlines and related parts, such as fasteners, as reusable footprints. During the board layout process, you can simply plop a board outline, along with perfectly-placed mounting holes into the editor and you can concentrate on placing components and routing. Also, having a standard library of board outlines gives you a predictable set of size choices for enclosures and for ordering SMD stencils.