Searching the Russian National Corpus
The Russian language has a vast and nuanced vocabulary. One approach to learning the vocabulary is to approach it in frequency order. The Nicholas Brown book seems dated and the frequency ordering methodology is not clear to me. Some words seem to be clustered by the beginning letter, which seems statistically unlikely. However, it’s a convenient list and I’m slowly building a table that cross-correlates the Nicholas Brown list with the methodologically-superior Russian National Corpus. To do that I harvested the data from the Corpus and built a Python application to search the database and report the rank and frequency data from it.
Creating a sqlite3 version of the Russian National Corpus
There is a CSV version of the Corpus, but the data is not useful for ordering in a meaningful way. Instead, I took the rank ordered tabular data from the page Частотный список лемм (Frequency list of lemmas) and simply pasted it into a Numbers spreadsheet. Since Numbers is extremely slow even on a fast-performing machine, it beachballed for nearly a minute during the paste operation. After that, I exported it as CSV. To get the CSV file into a sqlite3 database, I created a new table with the following schema:
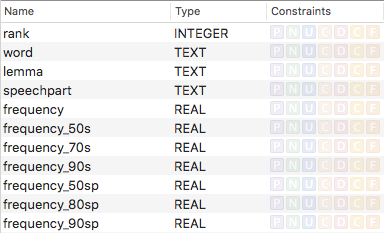
After mapping the column names to those in the CSV, the import was simple.
Accessing the sqlite3 version of the corpus using Python
Next I wrote a little Python application to access the data and return the rank or frequency of any Russian word. The only trick is that the Russian letter ë is rendered as e in the database; so any word containing ë must be altered before the search. Regular expressions to the rescue! To use the application, just launch it with -h help flag and you’ll see the calling format.
#!/usr/bin/python
# encoding=utf8
import sqlite3
import sys
import re
import argparse
# '/Users/alan/torrential/russian/vocabulary/RussianNationalCorpus'
# instantiate argument parser
parser = argparse.ArgumentParser(description='Search the Russian National Corpus')
# arguments
parser.add_argument('word', help='Russian word to search for')
parser.add_argument('db_path', help='Path to the sqlite db')
group = parser.add_mutually_exclusive_group()
group.add_argument('--r', action='store_true',help='Show rank order')
group.add_argument('--f', action='store_false',help='Show frequency in instances/million')
# parse
args = parser.parse_args()
word = args.word
replaced = re.sub('ё','е',word)
conn = sqlite3.connect(args.db_path)
col = "rank" if args.r else "frequency"
sql = "SELECT " + col + " FROM corpus WHERE word LIKE '" + replaced + "'"
curs = conn.cursor()
curs.execute(sql)
print curs.fetchone()[0]And a little AppleScript
Finally, I wrote an AppleScript wrapper that I can launch with a Quicksilver keystroke trigger. The wrapper takes the word off the clipboard and calls the Python app above, replacing the contents of the clipboard with the rank order of the word. For a little fun, it speaks the rank order number in Russian! Here’s the code for the AppleScript wrapper:
--
-- Created by: Alan Duncan
-- Created on: 2018-09-22
--
-- Copyright (c) 2018 Ojisan Seiuchi
-- Use to your heart's content; just give me a little credit
--
use AppleScript version "2.4" -- Yosemite (10.10) or later
use scripting additions
set dbPath to "/Users/alan/torrential/russian/vocabulary/RussianNationalCorpus"
set errorFlag to 0
set w to the clipboard
set cmd to "python /Users/alan/Documents/dev/scripts+tools/getRussianRank.py " & w & " " & dbPath & " --r"
try
set rank to do shell script cmd
set the clipboard to rank
on error errMsg
say "плохо"
set errorFlag to 1
end try
if errorFlag is 0 then
set saying to "Готово " & (rank as string)
say saying
end ifIf you want a pre-built sqlite3 version of the Russian National Corpus, here it is