After developing a rudimentary approach to detecting resistant language learning cards in Anki, I began teasing out individual factors. Once I was able to adjust the number of lapses for the age of the card, I could examine the effect of different factors on the difficulty score that I described previously.
Findings
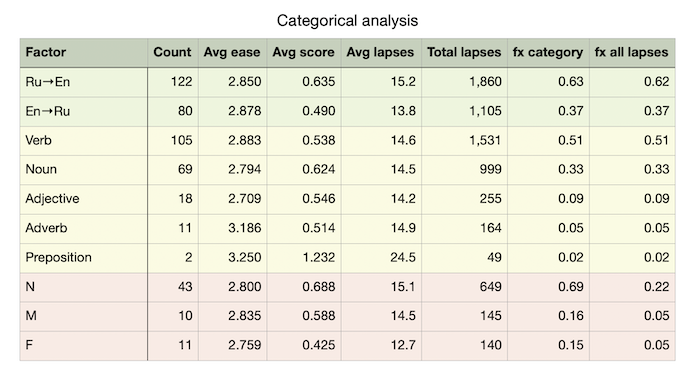
Some of the interesting findings from this analysis:
- Prompt-answer direction - 62% of lapses were in the Russian → English (recognition) direction.
- Part of speech - Over half (51%) of lapses were among verbs. Since the Russian verbal system is rich and complex, it’s not surprising to find that verb cards often fail.
- Noun gender - Between a fifth and a quarter (22%) of all lapses were among neuter nouns and among failures due to nouns only, neuter nouns represented 69% of all lapses. This, too, makes intuitive sense because neuter nouns often represent abstract concepts that are difficult to represent mentally. For example, the Russian words for community, representation, and indignation are all neuter nouns.
Interventions
With a better understanding of the factors that contribute to lapses, it is easier to anticipate failures before they accumulate. For example, I will immediately implement a plan to surround new neuter nouns with a larger variety of audio and sample sentence cards. For new verbs, I’ll do the same, ensuring that I include multiple forms of the verb, varying the examples by tense, number, person, aspect and so on.

{kind=link}