A deep dive into my Anki language learning: Part II (Vocabulary)
In Part I of my series on my Anki language-learning setup, I described the philosophy that informs my Anki setup and touched on the deck overview. Now I’ll tackle the largest and most complex deck(s), my vocabulary decks.
First some FAQ’s about my vocabulary deck:
- Do you organize it as L1 → L2 or as L2 → L1, or both? Actually, it’s both and more. Keep reading.
- Do you have separate subdecks by language level, or source, or some other characteristic? No, it’s just a single deck. First, I’m perpetually confused by how subdecks work. I’d rather subdecks just act as organizational, not functional, tools. But other users don’t see it that way. That’s why I use tags rather than subdecks to organize content.1
- Do you use frequency lists? No, I extract words from content that I’m reading, that I encounter when listening to moviews or podcasts, or words that my tutor mentions in conversation. That’s what goes in Anki.
Since this is a big topic, I’m going to start with a quick overview of the fields in the main note type that populates my vocabulary deck and then go into each one in more detail and how they fit together in each of my many card types. At the very end of the post, I’ll talk about verb cards which are similar in most ways to the straight vocabulary card, but which account from the complexities of the Russian verbal system.2
Before diving in, just note that I’m on version 2.1.49. For reasons.3
If you prefer to skip to a particular part of the post, here’s a quick outline:
Note fields
Note ID- like it says, the note ID. It’s because I don’t want to uniquely identify by the word, but by some other factor. Basically I reserve the right to have what Anki would otherwise consider duplicates.Front- this is the Russian (L2) wordPronunciation- the link to the audio file of the pronunciationBack- the English (L1) definitionsentence_ru- an example sentence in Russian (L2)sentence_en- the English (L1) translation of thesentence_ruNotes- notes about usage, always in Markdown. More on that later.Frequency- part of an abandoned idea, just too lazy to remove it.URL- if I have a link for more content on a word, it goes here. Mostly unused.Hint- This field is used to help disambiguate synonmys. It’s usually the first two letters + ellipsis.Synonyms- a list of synonymsRNC_frequency- the numerical frequency in the Russian National Corpus. If the word doesn’t appear in that corpus, just “NA”RussianDef- the Russian language definition of the wordrecognition_only- if non-empty, this field turns the card into a recognition-only card, meaning only L2 → L1ExpressionCloze1,ExpressionCloze2,ExpressionCloze3- these are flags for the Anki Cloze Anything script. More on this in a bit. This is such an important add-on that no-one knows about.image- if the word can be depicted in an image, this is where it goes@antonyms- like synonyms, but the oppositepronounce_sentence_ru- complicated to explain. For now, I’ll just say that it’s needed for the AwesomeTTS functionality.@is_numeral_card- if non-empty, this becomes a card for testing numbers. I’ll discuss that in a future post.@numeral_text- related to above@is_sentence_translation_card- another field that’s a little complicated to explain. I’ll discuss it in a future post about my sentence deck.
Card types
Now we can talk about the learner-facing (fun!) part of this. If you want to skip to a particular card type, they are L1 → L2, L2 → L1, Image → L2, L2 definition → L2 word.
L1 → L2 cards
For me these are just simple English (front side) to Russian (back side) cards.
And the back content:
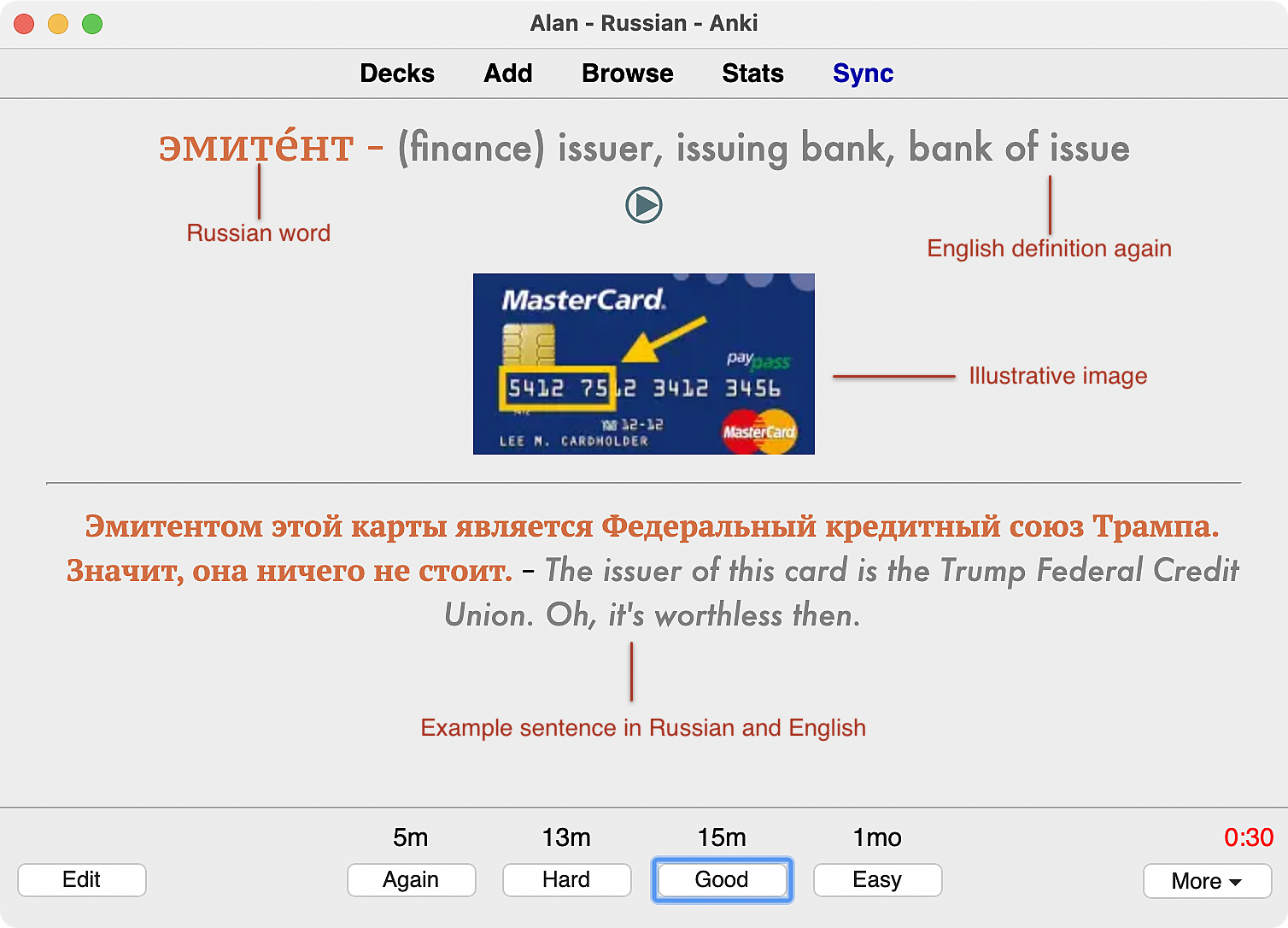
Since all of my vocabulary cards have pronunciations, the replay button appears on the card to hear the audio again. Of course, the audio only plays on the back side of this card. (Otherwise it would give away the answer!) The styling of the replay button is custom because the base styling makes the button absurdly large.
L2 → L1 cards
These, of course, display Russian on the front and English on the reverse.
And the back, fairly obvious, with annotations:
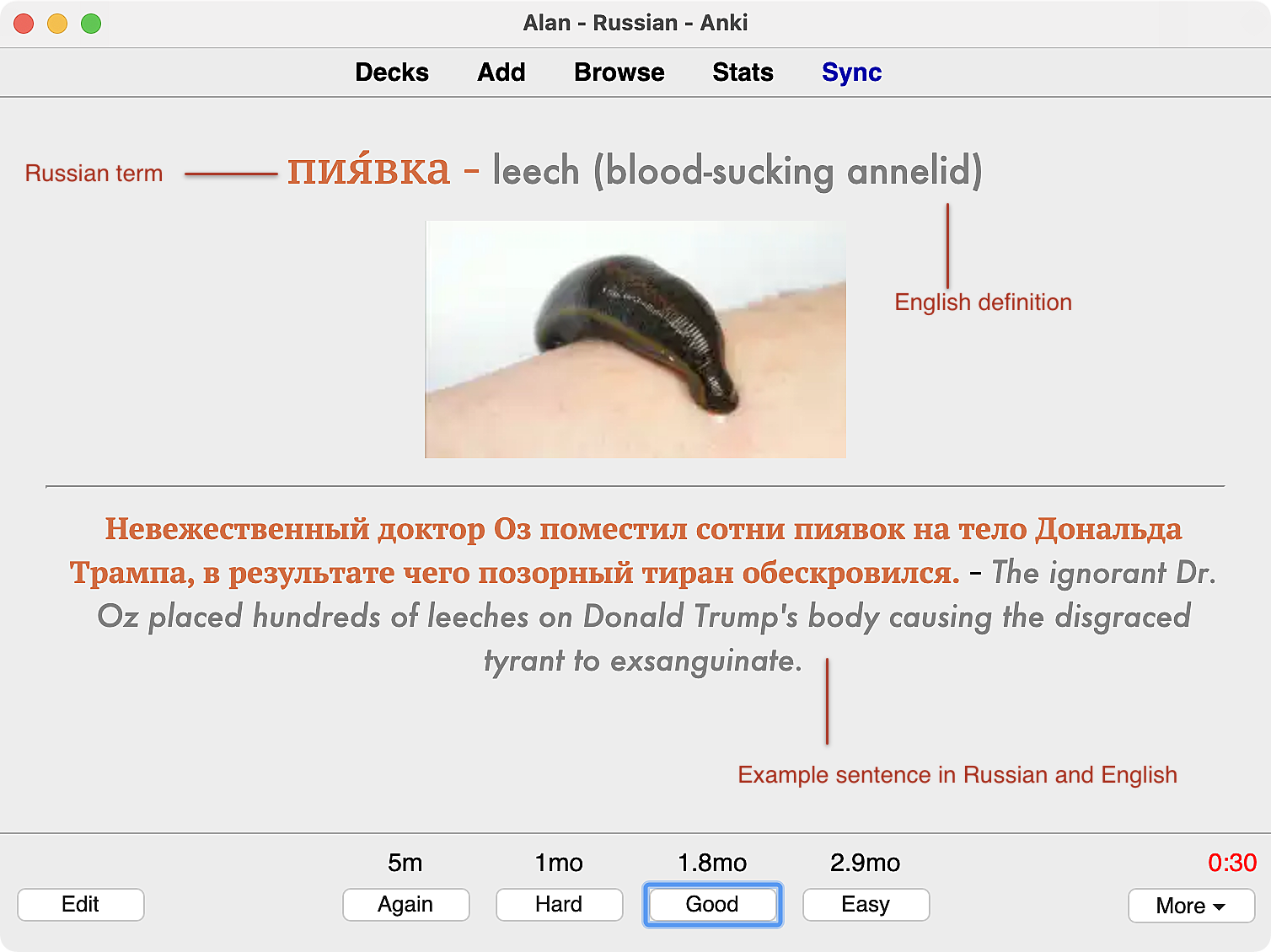
Image → L2 cards
Now onto some of the more interesting card types. Note that all of these card types are built from the same note. They take the field list above and just format them in different ways.
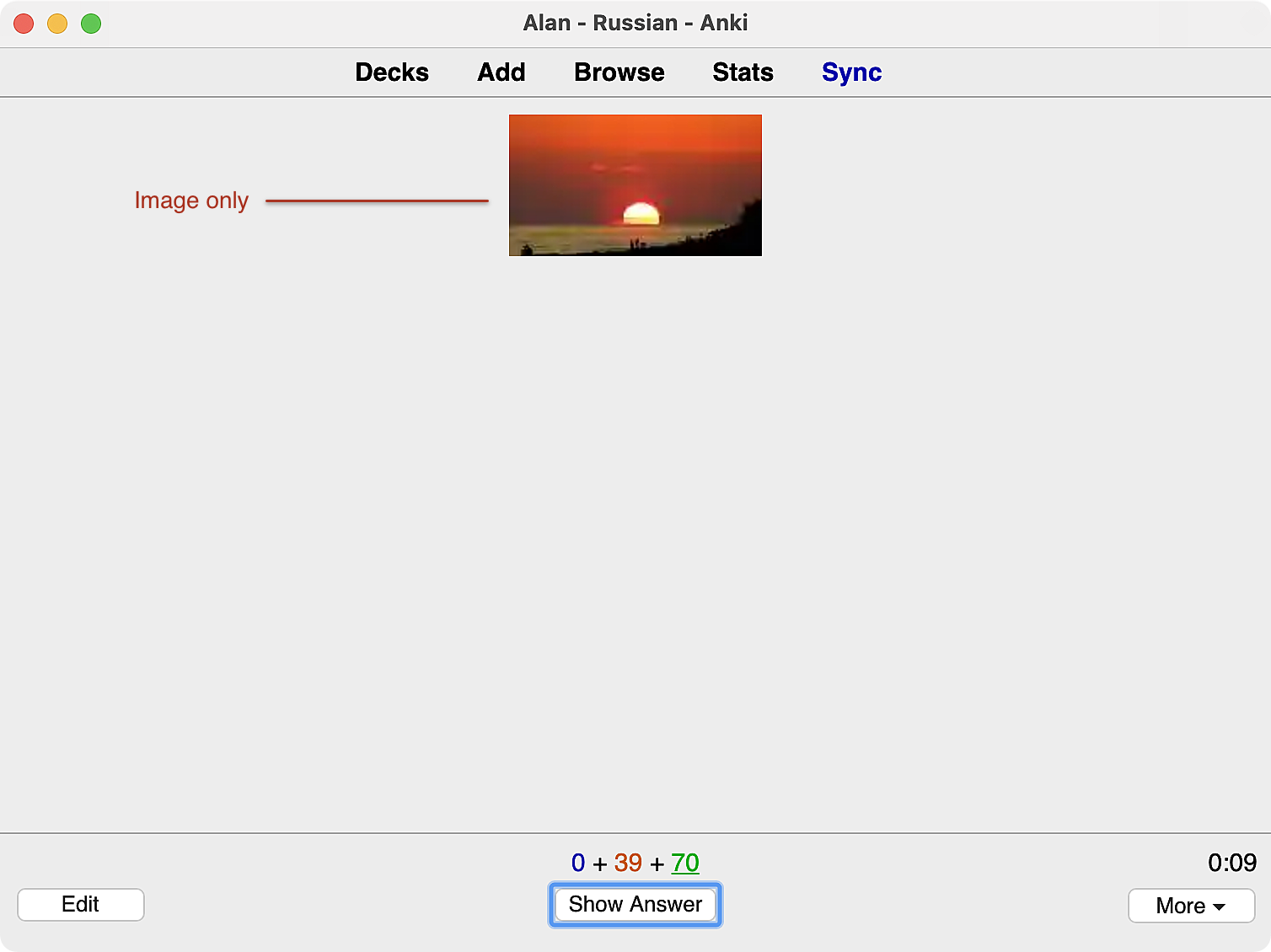
And on the reverse (answer) side:
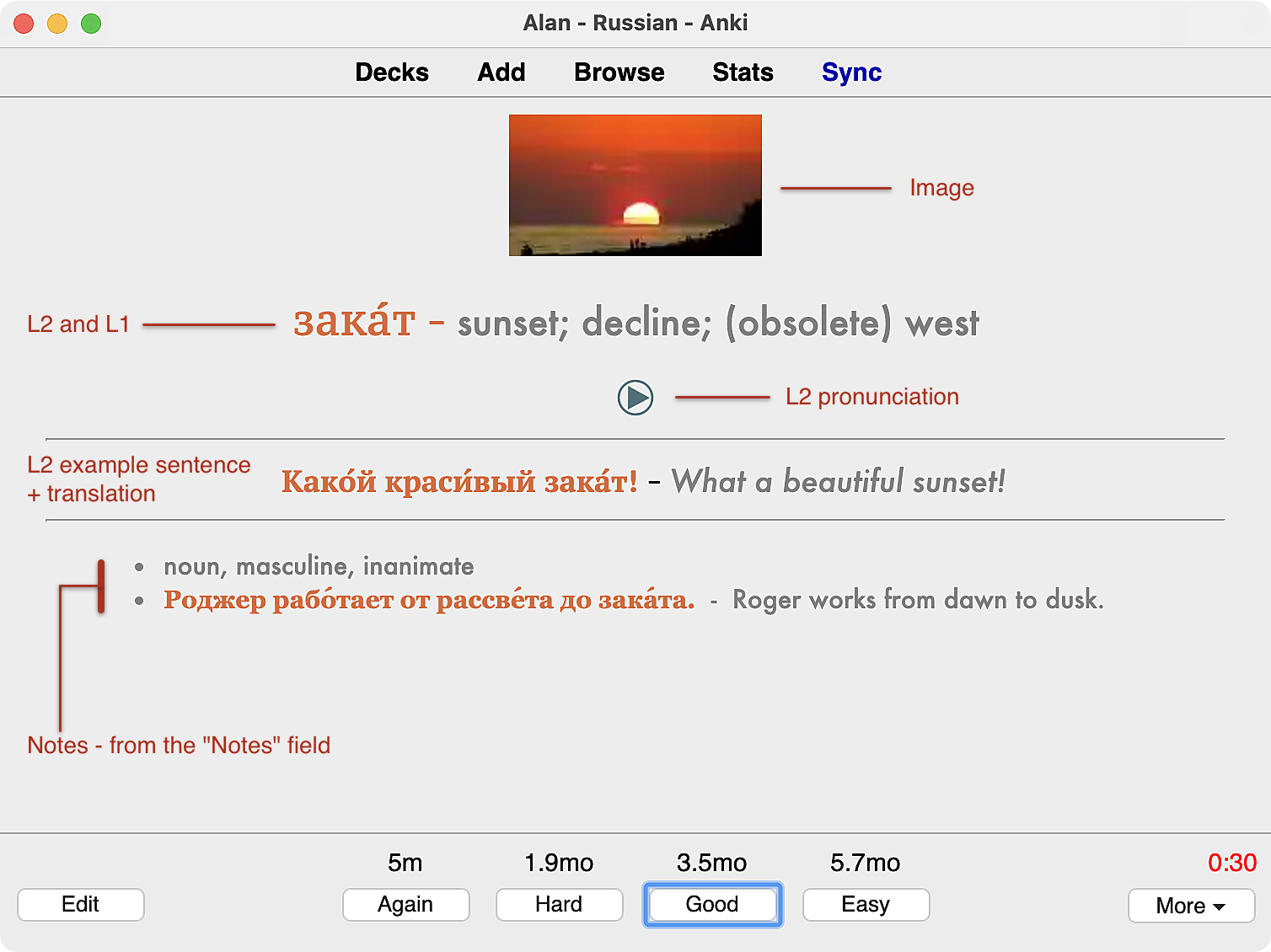
So far, this is the first time we’ve encountered a card with Notes. Whenever the Notes field is non-empty, we display it. This field is always assumed to contain HTML. But I don’t write out the HTML by hand. Instead, I write it in Markdown and I have a Keyboard Maestro macro that grabs the content from the editor field, transforms the Markdown content into HTML and pastes it into the HTML field editor. I’ve previously written in detail about the process of Generating HTML from Markdown in Anki fields
While we’re on a digression about Markdown and optional sections on my cards, I should mention two other optional sections: synonyms and antonyms. Not every card has this feature; but it looks like this:

These sections collapse and expand by clicking on the disclosure triangle.
L2 definition → L2 word
This isn’t quite a true monolingual card, but the intent is the same. On the front side is the L2 defintion and on the reverse is the L2 word (along with the L1 meaning and other information.)
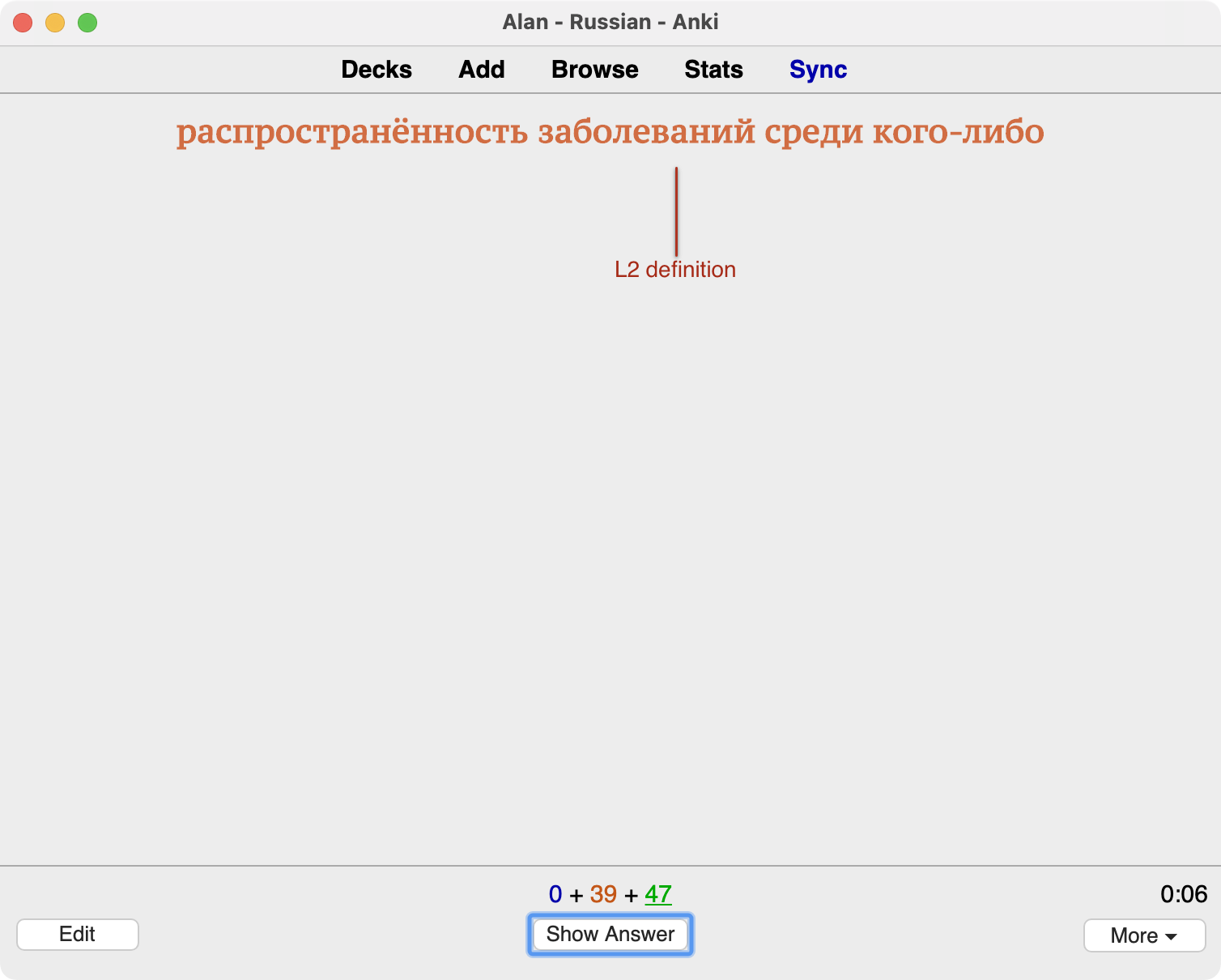
The back is a somewhat denser presentation than we’ve seen so far:
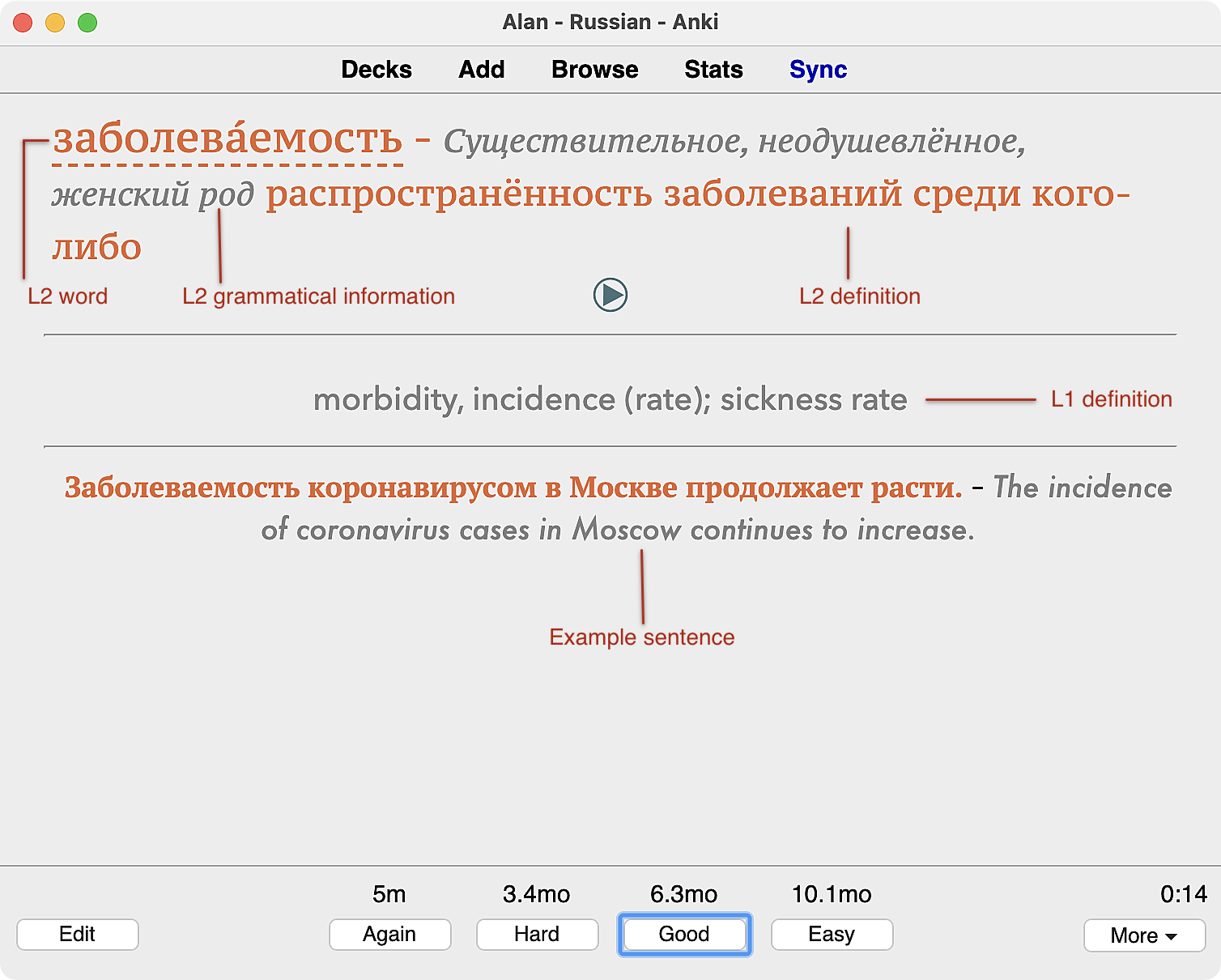
One new feature here is the appearance of grammatical information. The way I get this data should probably be its own post, but for now, I’ll describe it at a high level. I run an instance of russian_grammar_server that provides a number of endpoints, one of which is /pos. This API accepts a Russian word and returns part of speech information. The template for this card just makes a call to that server and then format the response on the card. If for some reason the server is unreachable, we just omit that info.
Process
Although I believe that making your own cards is the best way to acquire a useful vocabulary, not every part of the process is valuable. Time that I spend attending to extracting and formatting information takes away from the time that I could be studying. So my goal has been to automate these processes. Since almost all of these automations are finely tuned to my individual requirements, my hope is that you’ll be able to adopt some of the concepts that I use, if not the exact routines. Again, I use macOS and the solutions that I employ are heavily dependent on applications that run only on that OS. With those caveats, let’s talk about my process.
Researching words
When I research a new word, I want to know:
- the English language definition
- the Russian language (monolingual) definition
- the pronunciation
- an example sentence or two
For each of these elements, I have a single go-to site:
| Data needed | Site | URL |
|---|---|---|
| English definition | Wiktionary (en) | https://en.wiktionary.org/wiki/ |
| Russian definition | Викисловарь | https://ru.wiktionary.org/wiki/ |
| Pronunciation | Forvo | https://www.forvo.com |
| Example sentences | OpenRussian | https://www.openrussian.org |
Because each of these sites has a predictable URL pattern for loading words, I can use AppleScript to load the word into four adjacent tabs.
set searchTerm to the clipboard as text
set openRussianURL to "https://en.openrussian.org/ru/" & searchTerm
set wiktionaryURL to "https://en.wiktionary.org/wiki/" & searchTerm & "#Russian"
set forvoURL to "https://forvo.com/search/" & searchTerm & "/ru/"
set ruWiktionaryURL to "https://ru.wiktionary.org/wiki/" & searchTerm
tell application "Safari" to activate
-- load word definitions
tell application "Safari"
activate
set i to 0
set tabList to every tab of window 1
set tabCount to count of tabList
repeat tabCount times
tell window 1
set i to i + 1
set textURL to (URL of tab i) as text
-- load the word in open russian
if textURL begins with "https://en.openrussian.org" then
set encodedURL to urlEncode(openRussianURL) of me
set URL of tab i to encodedURL
end if
-- load the word in wiktionary
if textURL begins with "https://en.wiktionary.org" then
set URL of tab i to urlEncode(wiktionaryURL) of me
-- make the wiktionary tab the active tab
try
set current tab of window 1 to tab i
end try
end if
if textURL begins with "https://forvo.com" then
set URL of tab i to urlEncode(forvoURL) of me
end if
if textURL begins with "https://ru.wiktionary.org" then
set URL of tab i to urlEncode(ruWiktionaryURL) of me
end if
end tell
end repeat
end tell
-- encode Cyrillic test as "%D0" type strings
on urlEncode(input)
tell current application's NSString to set rawUrl to stringWithString_(input)
set theEncodedURL to rawUrl's stringByAddingPercentEscapesUsingEncoding:4 -- 4 is NSUTF8StringEncoding
return theEncodedURL as Unicode text
end urlEncodeI have a Keyboard Maestro macro that responds to ⌃L. For any word, I just copy it to the clipboard with ⌘V and then ⌃L to research. It’s a little more complicated if I encounter a word that’s in an inflected form. Then I have to use Wiktionary or some other source first to find the uninflected form.
The research macro does one more action which is to download the pronunciation file from Forvo. This is a little beyond the scope of what I wanted to present in this post; but I promise to write something about the forvodl tool that I wrote for this purpose.
Extracting word research data into Anki
Most of the heavy lifting here is done again by a Keyboard Maestro macro. All that’s necessary is to copy the word of interest to the clipboard and in the Anki new card editor, I active with macro with ⇧⌃L and the macro takes over. It uses UI navigation to move between fields in the note editor, stopping at each field to extract the relevant piece of information for that field. I’ll walk through some of those “stops” to discuss how I get the data.
Front field - Headword
The first field into which I extract research data is the Front field of the card. That’s the Russian (L2) word. To extract this word, which Wiktionary calls the headword, I use a custom tool I wrote called rheadword. It works by parsing the HTML of the Wiktionary page and extracting the element for the headword.
#!/usr/bin/env python3
from urllib.request import urlopen, Request
import urllib.parse
from random_user_agent.user_agent import UserAgent
from random_user_agent.params import SoftwareName, OperatingSystem, HardwareType
import copy
import re
import sys
from bs4 import BeautifulSoup
__version__ = 0.9
# accept word as either argument or on stdin
try:
raw_word = sys.argv[1]
except IndexError:
raw_word = sys.stdin.read()
raw_word = raw_word.replace(" ", "_").strip()
word = urllib.parse.quote(raw_word)
url = f'https://en.wiktionary.org/wiki/{word}#Russian'
hn = [HardwareType.COMPUTER.value]
user_agent_rotator = UserAgent(hardware_types=hn,limit=20)
user_agent = user_agent_rotator.get_random_user_agent()
headers = {'user-agent': user_agent}
try:
response = urlopen(Request(url, headers = headers))
except urllib.error.HTTPError as e:
if e.code == 404:
print("Error - no such word")
else:
print(f"Error: status {e.code}")
sys.exit(1)
# first extract the Russian content because
# we may have other languages. This just
# simplifies the parsing for the headword
new_soup = BeautifulSoup('', 'html.parser')
soup = BeautifulSoup(response.read(), 'html.parser')
for h2 in soup.find_all('h2'):
for span in h2.children:
try:
if 'Russian' in span['id']:
new_soup.append(copy.copy(h2))
# capture everything in the Russian section
for curr_sibling in h2.next_siblings:
if curr_sibling.name == "h2":
break
else:
new_soup.append(copy.copy(curr_sibling))
break
except:
pass
# use the derived soup to pick out the headword from
# the Russian-specific content
headwords = []
for strong in new_soup.find_all('strong'):
node_lang = strong.get('lang')
node_class = strong.get('class')
if node_lang == "ru":
if "Cyrl" in node_class:
if "headword" in node_class:
raw_headword = strong.text
headwords.append(raw_headword)
try:
print(headwords[0])
sys.exit(0)
except SystemExit:
# this just avoids triggering an exception due
# to a normal exit
pass
except IndexError:
# we didn't find any words
print("Error")
sys.exit(1)The macro simply pastes the output of the script and tabs for the next field.
Pronunciation field
Since we’ve already downloaded the pronunciation file from Forvo, what’s left is to insert it into the Anki note. Here we fire off a simple shell script that takes care of that.
#!/bin/zsh
USERDIR="/Users/$(whoami)"
APPSUPPORTDIR="$USERDIR/Library/Application Support/Anki2"
COLLDIR="$APPSUPPORTDIR/Alan - Russian"
MEDIARDIR="$COLLDIR/collection.media"
# locate the file we downloaded
FILE="$(ls $HOME/Documents/mp3 | head -1)"
# play it so we can hear
afplay "$HOME/Documents/mp3/$FILE"
# copy it to the collection.media directory
cp $HOME/Documents/mp3/$FILE "$MEDIARDIR/$FILE"
# insert the link in the Anki field
echo "[sound:$FILE]"English language definition field
As before, the macro tabs to the next field, where we need the English definition of the L2 word. And again, we employ a custom script for this. In a previous post Scraping Russian word definitions from Wikitionary: utility for Anki I’ve written about the process of extract definitions from Wiktionary. Better yet, since I’ve updated the process, take a look at the more robust script that I wrote about in A tool for scraping definitions of Russian words from Wikitionary.
Russian language definition field
Since once of my card types is monolingual (this one), I need to extract the Russian language definition. Again, another script. I use a technique similar to the one presented in this post; but of course the Russian Wiktionary page structure is different from the English version. There are also some interesting subtleties that have to be dealt with. Again, I promise to write about that, too!
Word frequency in Russian National Corpus
The macro now advances to the last field that we automatically complete. That field is the RNC_frequency field. The Russian National Corpus (RNC) is a comprehensive (though seemingly incomplete!) collection of words used in the Russian language. In the post Searching the Russian National Corpus I described the creation of a sqlite3 database of terms from the RNC. Essentially, this step in the macro is a just a script that searches that database for the term and fetches the frequency.
And that ends the process. In all, it takes a couple seconds to run through all of the extractions. The only work left is to identify an example sentence. While I could probably automate the extract of a sentence from Tatoeba, I’d prefer to not leave it to chance as some sentences are more suitable than others. So here, I do my own search. It’s also my chance to add one additional touch which involves create a cloze-type card from the sentence. But I’ll discuss that in the next installment on sentence cards.
Stuff I promised to write in more detail about
- Process for extract Russian language definitions from ru.wiktionary.org
- Extracting audio from the Forvi API
Longer term promises
- Release a sample deck - when 🤷🏻♂️
-
This isn’t always true as I have some legacy non-vocabulary decks that are organized by source. But there’s a reason for that which I’ll get to in a later post. ↩︎
-
Since Russian verbs mostly come in aspect pairs… ↩︎
-
As we go on, you’ll see that many of the scripts I use to efficiently create cards rely on AppleScript UI scripting. The > 2.1.49 updates completely break those features. At some point I will have to go through all of these scripts and update them. But for now, I’m staying with 2.1.49 because I’m too lazy to go through all of that. ↩︎